
LLM Command Generators
LLMCommandGenerators leverage in-context learning to output a list of commands that represent how the user wants to progress the conversation.
How an LLM-based Command Generator Work
The job of an LLM-based command generator is to ingest information about a conversation so far. It outputs a sequence
of commands that represent how the user wants to progress the conversation.
For example, if you defined a flow called transfer_money, and a user starts a conversation
by saying "I need to transfer some money", the correct command output would be StartFlow("transfer_money").
If you asked the user a yes/no question (using a collect step) and they say "yes.",
the correct command output is SetSlot(slot_name, True).
If the user answers the question but also requests something new, like "yes. Oh what's my balance?",
the command output might be [SetSlot(slot_name, True), StartFlow("check_balance")].
By generating a sequence of commands, Dialogue Understanding is a better way to represent what the user wants than a classification-based NLU system.
The LLM-based command generators also use a flow retrieval sub-module to ensure the input context size does not linearly scale up with the size of the assistant.
Types of LLM-based Command Generators
Rasa currently has two LLM-based command generators: SingleStepLLMCommandGenerator and MultiStepLLMCommandGenerator.
Deprecation Warning
The former LLMCommandGenerator has been renamed to SingleStepLLMCommandGenerator in version 3.9.0
while retaining its functionality.
Support for the former name LLMCommandGenerator will be removed in Rasa 4.0.0.
Please modify your assistant's configuration to use SingleStepLLMCommandGenerator instead.
To use one of the two CommandGenerators in your AI assistant, add the SingleStepLLMCommandGenerator or the
MultiStepLLMCommandGenerator to your NLU pipeline in the config.yml file.
Read more about the config.yml file here
and how to configure LLM models here
- SingleStepLLMCommandGenerator
- MultiStepLLMCommandGenerator
The SingleStepLLMCommandGenerator and MultiStepLLMCommandGenerator requires access to an LLM API. You can use any
OpenAI model that supports the /chat endpoint such as "gpt-3.5-turbo" or "gpt-4".
We are working on expanding the list of supported models and model providers.
info
The SingleStepLLMCommandGenerator works well with strong models, such as gpt-4, whereas the
MultiStepLLMCommandGenerator was designed to work well with cheaper and smaller models, such as gpt-3.5-turbo.
More information about recommended models can be found here
SingleStepLLMCommandGenerator
To interpret the user's message in context, the current implementation of the SingleStepLLMCommandGenerator uses
in-context learning, information about the current state of the conversation, and flows defined in your assistant.
Descriptions and slot definitions of each flow are included in the prompt as relevant information. However, to
scale to a large number of flows, the LLM-based command generator includes only the flows that are relevant to the current
state of the conversation, see flow retrieval.
Prompt Template
The default prompt template serves as a dynamic framework enabling the SingleStepLLMCommandGenerator
to render prompts. The template consists of a static component, as well as
dynamic components that get filled in when rendering a prompt:
- Current state of the conversation - This part of the template captures the ongoing dialogue.
- Defined flows and slots - This part of the template provides the context and structure for the conversation. It outlines the overarching theme, guiding the model's understanding of the conversation's purpose.
- Active flow and slot - Active elements within the conversation that require the model's attention.
Customization
You can customize the SingleStepLLMCommandGenerator as much as you wish.
General customization options that are available for both LLMCommandGenerators are listed in the section
General Customizations.
Customizing the Prompt Template
If you cannot get something to work via editing the flow and slot descriptions (see section
customizing the prompt), you can go one level deeper
and customise the prompt template used to drive the SingleStepLLMCommandGenerator.
To do this, write your own prompt as a jinja2 template and provide it to the component as a file:
Deprecation Warning
The former LLMCommandGenerator's prompt configuration is replaced by SingleStepLLMCommandGenerator's prompt_template in version 3.9.0.
The prompt configuration variable is now deprecated and will be removed in version 4.0.0.
The prompt template also allows the utilization of variables to incorporate dynamic information. You can access the comprehensive list of available variables here to use in your custom prompt template.
| Variable | Type | Description |
|---|---|---|
available_flows | List[Dict[str, Any]] | A list of all flows available in the assistant. |
current_conversation | str | A readable representation of the current conversation. a simple example: USER: hello\nAI: hi\nUSER: I need to send money |
current_flow | str | ID of the current active flow. example: transfer_money |
current_slot | str | Name of the currently asked slot. example: transfer_money_recipient |
current_slot_description | str | Description of the currently asked collect step. example: the name of the person |
flow_slots | List[Dict[str, Any]] | A list of slots from the current active flow. |
user_message | str | The latest message sent by the user. example: I want to transfer money |
- Iterating over the
flow_slotsvariable can be useful to create a prompt that lists all the slots of the current active flow,
| Variable | Type | Description |
|---|---|---|
slot.name | str | Name of the slot. example: transfer_money_has_sufficient_funds |
slot.description | str | Description of the slot. example: Checks if there is sufficient balance |
slot.value | str | Value of the slot. example: True |
slot.type | str | Type of the slot. example: bool |
slot.allowed_values | List[str] | List of allowed values for the slot. example: [True, False] |
- Iterating over the
available_flowsvariable can be useful to create a prompt that lists all the flows,
| Variable | Type | Description |
|---|---|---|
flow.name | str | Name of the flow. example: transfer_money |
flow.description | str | Description of the flow. example: This flow lets users send money. |
flow.slots | List[Dict[str, Any]] | A list of slots from the flow. |
MultiStepLLMCommandGenerator
The MultiStepLLMCommandGenerator also uses in-context learning to interpret the user's message in context,
but breaks down the task into several steps to make the job of the LLM easier. The component was designed to
enable cheaper and smaller LLMs, such as gpt-3.5-turbo, as viable alternatives to costlier but more powerful
models such as gpt-4.
The steps are:
- handling the flows (starting, ending, etc.) and
- filling out the slots
Accordingly, instead of just a single prompt that handles everything, the MultiStepLLMCommandGenerator has two prompts:
handle_flowsandfill_slots.
The following diagram shows which prompt is used when:
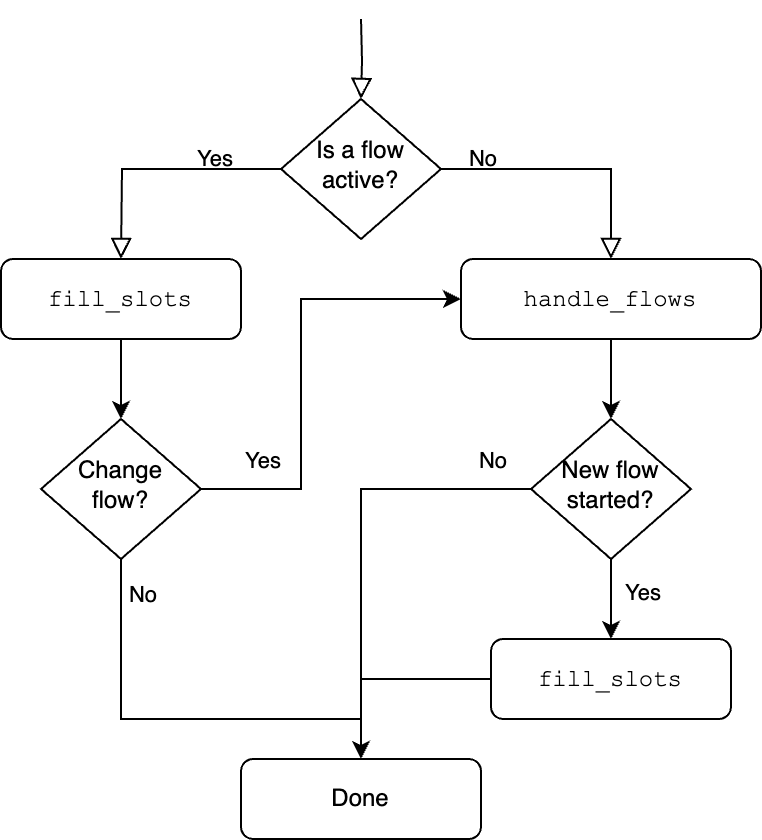
If no flow is currently active, the handle_flows prompt is used to start or clarify flows.
If a flow is started, next the fill_slots prompt is executed to fill any slots of the newly started flow.
If a flow is currently active, the fill_slots prompt is called to fill any new slots of the currently active flow.
If the user message (also) indicates that, for example, a new flow should be started or the active flow should be
canceled, a ChangeFlow command is triggered. This results in calling the handle_flows prompt to start, cancel,
or clarify flows. If that prompt leads to starting a flow, the fill_slots prompt is executed again to fill any slots
of that new flow.
Prompt Templates
The default prompt templates serve as a dynamic framework enabling the MultiStepLLMCommandGenerator
to render prompts. The templates consists of a static component, as well as
dynamic components that get filled in when rendering a prompt.
- handle_flows
- fill_slots
- Current state of the conversation: This part of the template captures the ongoing dialogue.
- Defined flows: This part of the template provides the context and structure for the conversation. It outlines the overarching theme, guiding the model's understanding of the conversation's purpose.
- Active flow: Displays the name of the current active flow (if any). Used within conditional statements to customize the message about the flow's status.
Customization
You can customize the MultiStepLLMCommandGenerator as much as you wish.
General customization options that are available for both LLMCommandGenerators are listed in the section General Customizations.
Customizing The Prompt Template
If you cannot get something to work via editing your flow and slot descriptions (see section
customizing the prompt), you can go one level deeper
and customise the prompt templates used to drive the MultiStepLLMCommandGenerator.
To do this, write your own prompt as a jinja2 template and provide it to the component as a file:
You can customize both prompts using the example configuration above, or you can choose to customize only a specific prompt.
The prompt template also allows the utilization of variables to incorporate dynamic information.
handle_flows
Here is a comprehensive list of available variables to use in your custom handle_flows prompt template:
| Variable | Type | Description |
|---|---|---|
available_flows | List[Dict[str, Any]] | A list of all flows available in the assistant. |
current_conversation | str | A readable representation of the current conversation. a simple example: USER: hello\nAI: hi\nUSER: I need to send money |
current_flow | str | ID of the current active flow. example: transfer_money |
last_user_message | str | The latest message sent by the user. example: I want to transfer money |
- Iterating over the
available_flowsvariable can be useful to create a prompt that lists all the flows,
| Variable | Type | Description |
|---|---|---|
flow.name | str | Name of the flow. example: transfer_money |
flow.description | str | Description of the flow. example: This flow lets users send money. |
By default following commands can be predicted in this step: StartFlow, Clarify, CancelFlow, CannotHandle.
fill_slots
Here is a comprehensive list of available variables to use in your custom fill_slots prompt template:
| Variable | Type | Description |
|---|---|---|
available_flows | List[Dict[str, Any]] | A list of all flows available in the assistant. |
current_conversation | str | A readable representation of the current conversation. a simple example: USER: hello\nAI: hi\nUSER: I need to send money |
current_flow | str | ID of the current active flow. example: transfer_money |
current_slot | str | Name of the currently asked slot. example: transfer_money_recipient |
current_slot_description | str | Description of the currently asked collect step. example: the name of the person |
current_slot_type | str | The type of the current slot. example: the name of the person |
current_slot_allowed_values | str | The allowed values or options for the slot currently being asked for within the active flow. example of allowed values for a slot: Size: [Small, Medium, Large] |
flow_slots | List[Dict[str, Any]] | A list of slots from the current active flow. |
last_user_message | str | The most recent message sent by the user. example: I want to transfer money |
top_flow_is_pattern | bool | Indicates whether the current active flow is a pattern. |
top_user_flow | Flow | The top user flow object in the internal dialog stack. |
top_user_flow_slots | List[Dict[str, Any]] | The slots associated with the top user flow. |
flow_active | bool | Indicates whether a flow is currently active. |
- Iterating over the
flow_slotsor thetop_user_flow_slotsvariable can be useful to create a prompt that lists all the slots of the current active flow (can be a pattern) or the top user flow,
| Variable | Type | Description |
|---|---|---|
slot.name | str | Name of the slot. example: transfer_money_has_sufficient_funds |
slot.description | str | Description of the slot. example: Checks if there is sufficient balance |
slot.value | str | Value of the slot. example: True |
slot.type | str | Type of the slot. example: bool |
slot.allowed_values | List[str] | List of allowed values for the slot. example: [True, False] |
- Iterating over the
available_flowsvariable can be useful to create a prompt that lists all the flows,
| Variable | Type | Description |
|---|---|---|
flow.name | str | Name of the flow. example: transfer_money |
flow.description | str | Description of the flow. example: This flow lets users send money. |
By default only SetSlot commands can be predicted in this step.
Prompt Tuning
Apart from the prompt customization proposed in the section on Customizing The Prompt, the
MultiStepLLMCommandGenerator might benefit from some additional prompt tuning.
Few-shot learning
Few-shot learning is a machine learning approach in which an AI model learns to make accurate predictions by being trained
on a very small number of labeled examples.
Our internal experiments showed that adding some examples of user message to command pairs to the prompt template
handle_flows helped to improve the performance of the LLM, especially for the Clarify command.
To do so, curate a small list of user message - action list pairs of examples that are specific to the domain of your assistant. Next, you can add them to the prompt template handle_flows after
line 22. Here is an example:
Language of the prompt
In our internal experiments, we have found that smaller LLMs benefit from having the complete prompt in a single language. Hence, if your assistant is built to understand and respond to a user in a language other than English and the flows descriptions as well as the collect step descriptions are in that same language, the LLM might benefit from translating the prompt template to that language as well. For example, assume users are talking in German to your assistant and the flow descriptions and collect step descriptions are also in German. To simplify the job of the LLM it might help to translate the complete prompt template to German as well.
You can use strong LLMs, such as gpt-4, for translating.
However, we recommend to manually check the prompt templates after translating it automatically.
Formatting
In both prompt templates, handle_flows and fill_slots, we iterate over the flows and/or the slots.
Depending on the descriptions you wrote for those, it might make sense to update the for loop in the prompt templates.
For example, if your slot descriptions are rather long and contain a list of bullet points, the slot list in the final prompt might look like this:
As you see it is quite hard to distinguish between the description and the actual slots.
To help the LLM to clearly distinguish between the slot and the description, we recommend to update the for loop in the jinja2 prompt template as follows:
This results in the following:
Current Limitations
The MultiStepLLMCommandGenerator will be able to generate the following commands:
- in
handle_flowsstep:StartFlow,Clarify,CancelFlow,CannotHandle. - in
fill_slotsstep:SetSlot. The CannotHandle command will be triggered from thehandle_flowsprompt when the scope of the user message is beyond starting, canceling, or clarifying a flow. The command will trigger the cannot handle pattern to indicate that the user message can not be treated as expected.
Retrieving Relevant Flows
As your assitant's skill set evolves, the number of functional flows will likely expand into the hundreds. However, due to the constraints of the LLM's context window, it is impractical to present all these flows simultaneously to the LLM. To ensure efficiency, only a subset of flows that are relevant to a given conversation will be considered. We implement a flow retrieval mechanism to identify and filter the most relevant flows for the command generator. This targeted selection helps in crafting effective prompts that are within the limit of the LLM's context window.
LLM Context Window Limitation
The LLM-based command generator operates within the confines of a predefined context window of the underlying model, which limits the volume of text it can process at one time. This window encompasses all the text the model can "view" and utilize for decision-making (the prompt) and response generation (the output).
warning
The flow retrieval mechanism only filters the relevant flows, while the reasoning and decision on how to proceed (given the flows identified as relevant) lies with the command generator.
The ability to retrieve relevant flows has a training component attached to it. During training, all defined flows
with flow guards potentially evaluating to true are transformed into documents
containing flow descriptions and (optionally) slot descriptions and allowed slot values.
These documents are then transformed into vectors using the embedding model and stored in a vector store.
When talking to the assistant, i.e. during inference, the current conversation context is transformed into a vector
and compared against the flows in the vector store. This comparison identifies the flows that are most similar to the
current conversation context and includes them into the prompt of the SingleStepLLMCommandGenerator and
the MultiStepLLMCommandGenerator.
However, additional rules are applied to select or discard certain flows:
- Any flow with a flow guard evaluating to
Falseis excluded. - Any flow marked with the
always_include_in_promptproperty set totrueis always included, provided that the flow guard(if defined) evaluates totrue. - All flows that are active during the current conversation context are always included.
This feature of retrieving only the relevant flows and including them in the prompt is enabled by default. Read more about configuring the options here.
The performance of the flow retrieval depends on the quality of flow descriptions. Good descriptions improve the differentiation among flows covering similar topics but also boost the alignment between the intended user actions and the flows. For tips on how to write good descriptions, you can check out our guidelines.
General Customization
The following customizations are available for the SingleStepLLMCommandGenerator as well as for the MultiStepLLMCommandGenerator.
LLM configuration
To specify the OpenAI model to use for the SingleStepLLMCommandGenerator or the MultiStepLLMCommandGenerator, set the
llm.model_name property in the config.yml file:
The model_name defaults to gpt-4 for the SingleStepLLMCommandGenerator and defaults to gpt-3.5-turbo for the
MultiStepLLMCommandGenerator. The model name should be set
to a chat model of OpenAI.
Similarly, you can specify the request_timeout and temperature parameters for the LLM.
The request_timeout defaults to 7 seconds and the temperature defaults to 0.0.
If you want to use Azure OpenAI Service, configure the necessary parameters as described in the Azure OpenAI Service section.
Using Other LLMs
By default, OpenAI is used as the underlying LLM provider.
The LLM provider you want to use can be configured in the config.yml file. To use another provider, like cohere:
For more information, see the LLM setup page on llms and embeddings
Customizing The Prompt
Because the LLMCommandGenerators use in-context learning, one of the primary ways
to tweak or improve performance is to customize the prompt.
In most cases, you can achieve what you need by customizing the description fields in your flows.
Every flow has its own description field; optionally, every step in your flow can also have one.
If you notice a flow is triggered when it shouldn't, or a slot is not extracted correctly,
adding more detail to the description will often solve the issue.
For example, if you have a transfer_money flow with a collect step for the slot amount, you can add a description
to extract the value more reliably:
Use the following guidelines to write informative and contextually rich flow descriptions.
- Provide information-dense descriptions: Ensure flow descriptions are precise and informative, directly outlining the flow's purpose and scope. Aim for a balance between brevity and the density of information, using imperative language and avoiding unnecessary words to prevent ambiguity. The goal is to convey essential information as clearly as possible.
- Use clear and standard language: Avoid unusual phrasing or choice of words. Stick to clear, universally understood language.
- Explicitly define context: Explicitly define the flow context to increase the models situational awareness. The embedding models used for retrieving only the relevant flows lacks situational awareness. It can't figure out the context or read between the lines beyond what's directly described in the flow.
- Clarify implicit knowledge: Clarify any specialized knowledge in descriptions (e.g. if there are brand names mentioned: what is brand domain; if the product name is mentioned: what is the product about). The embedding model that is used for retrieving only the relevant flows is unlikely to produce good embeddings regarding brands and their products.
- (Optional) Adding example user utterances: While strictly not required, adding example user utterances can add more context to the flow descriptions. This can also ensure that the embeddings will closely match the user inputs. This should be considered more as a remedy, rather than a cure. If user utterances improve performance, it suggests they provide new information that could be directly incorporated into flow descriptions.
Customizing flow retrieval
The ability to retrieve only the relevant flows for inclusion in the prompt at inference time is activated by default.
To configure it, you can modify the settings under the flow_retrieval property. The default configuration uses
text-embedding-ada-002 embedding model from OpenAI:
You can adjust the embedding provider and model. More on supported embeddings and how to configure those can be found here.
Additionally, you can also configure:
turns_to_embed- The number of conversation turns to be transformed into a vector and compared against the flows in the vector store. Setting the value to 1 means that only the latest conversation turn is used. Increasing the number of turns expands the conversation context window.should_embed_slots- Whether to embed the slot descriptions along with the flow description during training (True / False).num_flows- The maximum number of flows to be retrieved from the vector store.
Below is a configuration with default values:
Number of retrieved flows
The number of flows specified by num_flows does not directly correspond to the actual number of flows included
into the prompt. The total number of included flows also depends on the flows marked as
always_include_in_prompt and those previously active. For more information, check the Retrieving Relevant Flows
section.
The flow retrieval can also be disabled by setting the flow_retrieval.active field to false:
:::warn Disabling the ability to retrieve only the flows that are relevant to the current conversation context will restrict the command generator's capacity to manage a large number of flows. Due to the command generator's limited prompt size, exceeding this limit will lead to its inability to create effective commands, leaving the assistant unable to provide meaningful responses to user requests. Additionally, a high number of tokens in the prompt can result in increased costs and latency, further impacting the responsiveness of the system. :::
Customizing the maximum length of user input
To restrict the length of user messages, set the user_input.max_characters (default value 420 characters).