
Architecture
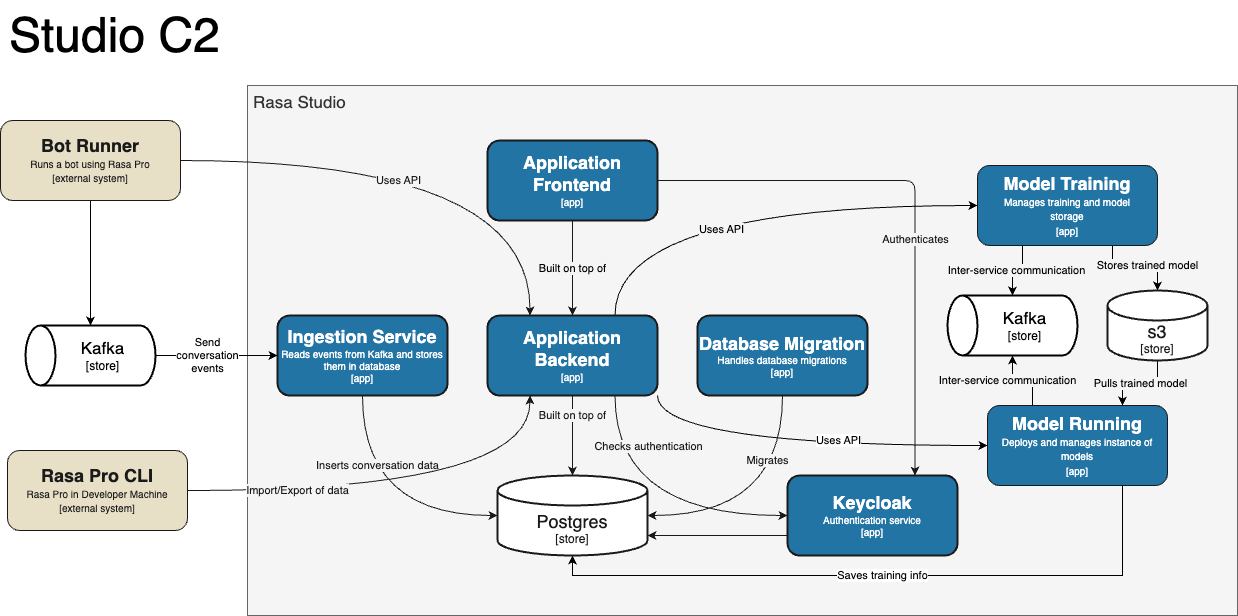
High Level Architecture
Below is a high level architecture diagram of Rasa Studio. The diagram shows the main components of Rasa Studio and how they interact with each other.
Please click on the image to view it in full size.
Containers
The below image shows the different containers that make up Rasa Studio. The containers are deployed on a Kubernetes cluster.
Please click on the image to view it in full size.
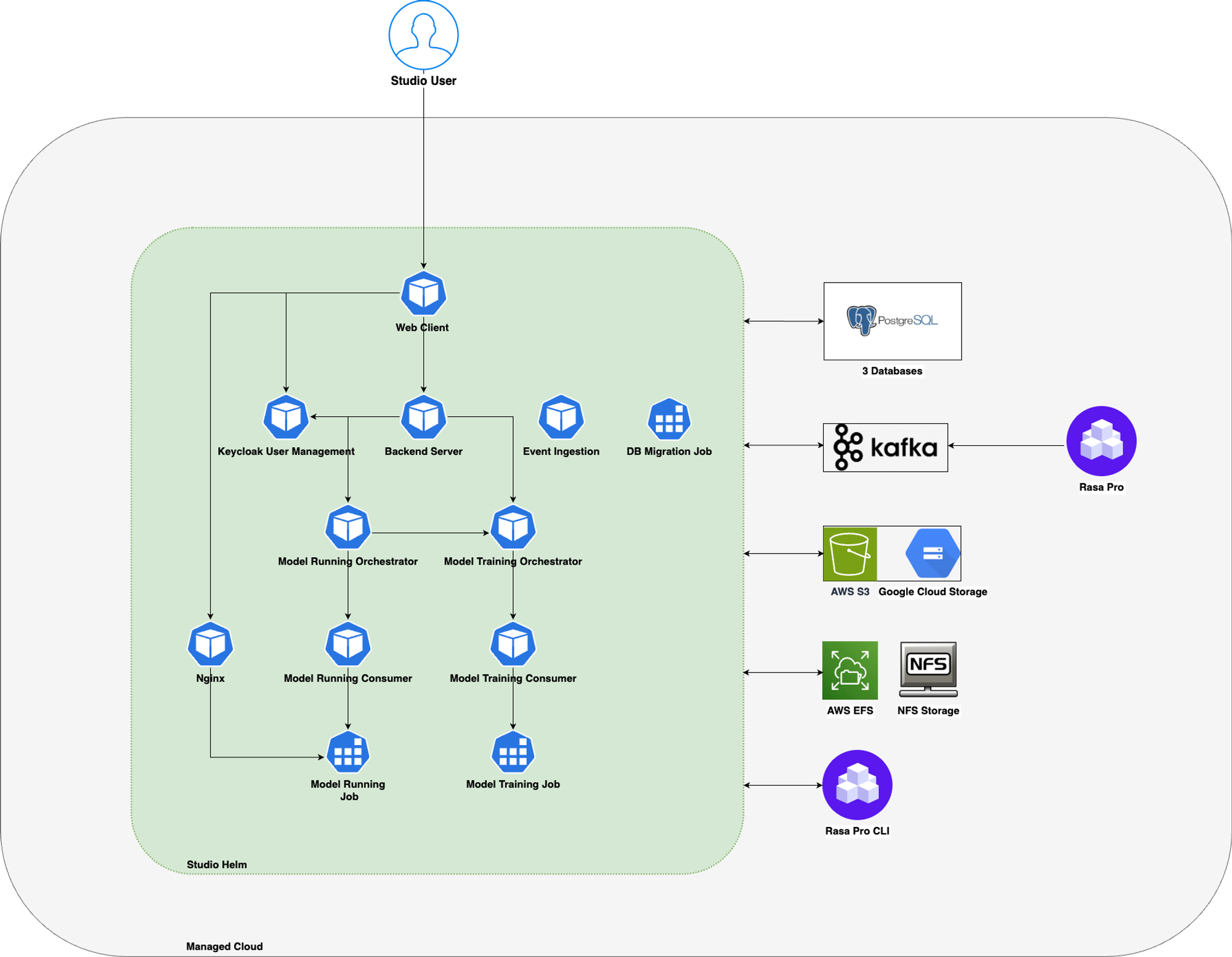
The following container images are part of the Studio deployment:
Studio Web Client Container: This container hosts the frontend service of Rasa Studio. It provides a user-friendly web interface that allows users to interact with and manage their conversational AI projects.
Studio Backend Server Container: The Studio backend server container hosts the backend service of Rasa Studio. It processes incoming requests, executes application logic and manages data. The backend server exposes APIs that the web client interacts with to perform various actions in the UI. It also exposes APIs for a developer user to use
Rasa Pro StudioCLI commands to pull/push data from/to Studio.Studio Database Migration Server Container: This container is used specifically for running database migrations during deployment or upgrades of Rasa Studio. It ensures that the database schema is up to date and compatible with the latest version of Rasa Studio. This container runs as a Kubernetes job during deployment.
Studio Keycloak Container: Studio uses Keycloak as its user management system. The Keycloak container provides authentication, authorization, and user management capabilities for Rasa Studio. It handles user registration, login, password management, and access control to ensure secure access to Studio's features and functionalities.
Studio Ingestion Service Container: The Studio Ingestion Service container is responsible for ingesting conversation events from Rasa Pro assistant (classic assistant mode) via the Kafka broker. It listens to the specified Kafka topic, receives bot events, and processes them for storage and analysis within Rasa Studio.
Studio Model Service Containers: These are a group of services that take care of training and running an assistant model in the Studio. This powers the
try your assistantfeature where a user can try the modern assistant that they created and trained. Below are the containers that are part of this service:- model-training service orchestrator
- model-training service consumer
- model-running service orchestrator
- model-running service consumer
- model-training rasa container job - Runs a Rasa Pro container image (supports version 3.7.0 & above)
- model-running rasa container job - Runs a Rasa Pro container image (supports version 3.7.0 & above)
When training is triggered from the UI, Studio creates a new Kubernetes job to train a model. This temporary training job is removed when the model is trained. The model is saved in a cloud storage. It then runs another Kubernetes job to pull the trained model from cloud storage and run the trained model. This model is then used in
try your assistantfeature to talk to the assistant.tip
Please be aware that increasing the number of
model-training service consumerreplicas in your deployment allows for a greater capacity to conduct assistant training in parallel. If you have triggered more training jobs than the number of replicas ofmodel-training service consumer, the training jobs will be queued and will be processed as soon as amodel-training service consumerbecomes available.tip
The number of replicas of
model-running service consumeris directly proportional to the number of assistants that can be supported in Studio. If you expect to create4assistants, it is recommended to create at leastnumber of assistants + 1replicas ofmodel-running service consumer. There should always be a freemodel-running service consumeravailable to run a newly trained model. If you expect to train a lot more often, setting a replica count of number ofnumber of assistants * 2will gurantee that there is always a freemodel-running service consumeravailable to run a newly trained model.