
Custom Graph Components
You can extend Rasa with custom NLU components and policies. This page provides a guide on how to develop your own custom graph components.
Rasa provides a variety of NLU components and policies out of the box. You can customize them or create your own components from scratch by using custom graph components.
To use your custom graph component with Rasa it has to fulfill the following requirements:
- It has to implement the
GraphComponentinterface - It has to be registered with the used model configuration
- It has to be used in the configuration file
- It has to use type annotations. Rasa makes use of the type annotations
to validate your model configuration.
Forward references
are not allowed. If you're using Python 3.7 you can use
from __future__ import annotationsto get rid of forward references.
Graph Components
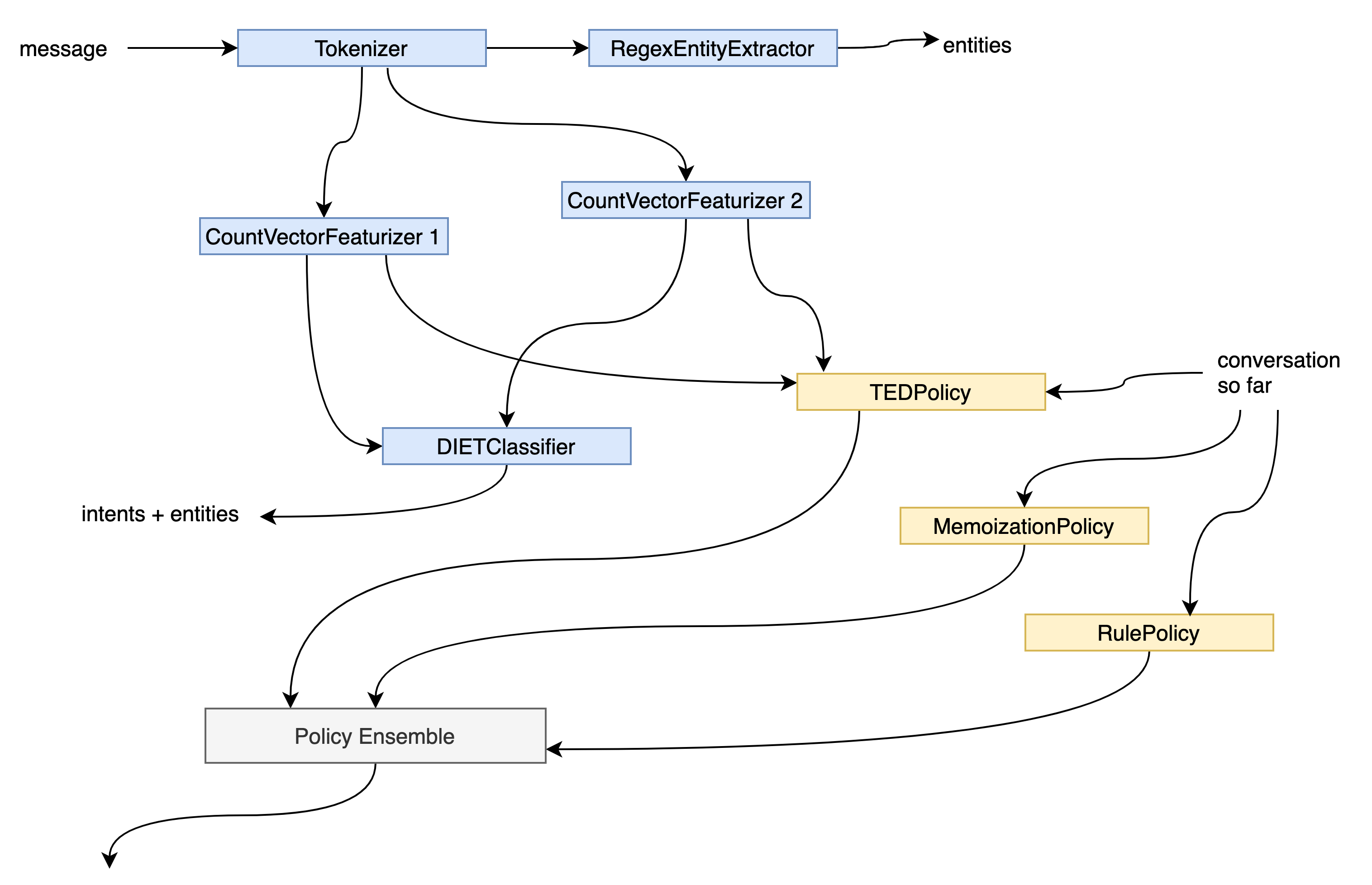
Rasa uses the passed in model configuration to build a directed acyclic graph. This graph describes the dependencies between the items in your model configuration and how data flows between them. This has two major benefits:
- Rasa can use the computational graph to optimize the execution of your model. Examples for this are efficient caching of training steps or executing independent steps in parallel.
- Rasa can represent different model architectures flexibly. As long as the graph remains acyclic Rasa can in theory pass any data to any graph component based on the model configuration without having to tie the underlying software architecture to the used model architecture.
When translating the model configuration to the computational graph
policies and NLU components become nodes within this graph.
While there is a distinction between policies and NLU components in your model
configuration, the distinction is abstracted away when they are placed within the graph.
At this point policies and NLU components become abstract graph components.
In practice this is represented by the
GraphComponent
interface: Both policies and NLU components have to inherit from this interface to
become compatible and executable for Rasa's graph.
Getting Started
Before you get started, you have to decide whether you want to implement a custom
NLU component or a policy. If you are implementing
a custom policy, then we recommend extending the existing
rasa.core.policies.policy.Policy class which already implements the GraphComponent
interface.
If you want to implement a custom NLU component then start out with the following skeleton:
Read the following sections to find out how to solve the TODOs in the example above
and what other methods need to be implemented in your custom component.
custom tokenizers
If you create a custom tokenizer, you should extend the
rasa.nlu.tokenizers.tokenizer.Tokenizer class. The train and process methods are
already implemented so you only need to overwrite the tokenize method.
The GraphComponent interface
To run your custom NLU component or policy with Rasa it must implement the GraphComponent interface.
create
The create method is used to instantiate your graph component during training and has to be
overridden. Rasa passes the following parameters when calling the method:
config: This is your component's default configuration merged with the configuration provided to the graph component in the model configuration file.model_storage: You can use this to persist and load your graph component. See the model persistence section for further details on its usage.resource: The unique identifier of your component within themodel_storage. See the model persistence section for further details on its usage.execution_context: This provides additional information about the current mode of execution:model_id: A unique identifier for the model used during inference. This parameter isNoneduring training.should_add_diagnostic_data: IfTruethen additional diagnostic metadata should be added to your graph component's predictions on top of the actual prediction.is_finetuning: IfTruethen the graph component can be trained using finetuning.graph_schema: Thegraph_schemadescribes the computational graph which is used to train your assistant or to make predictions with it.node_name: Thenode_nameis a unique identifier for the step in the graph schema which is fulfilled by the called graph component
load
The load method is used to instantiate your graph component during inference. The default
implementation of this method calls your create method. It is recommended to override
this if your graph component
persists data as part of the training.
See create for a description of the individual parameters.
get_default_config
The method get_default_config returns the default configuration for your graph
component. Its default implementation returns an empty dictionary which implies that
the graph component
does not have any configuration. Rasa will update the default configuration with the given
in the configuration file at runtime.
supported_languages
The method supported_languages specifies which
languages
a graph component supports.
Rasa will use the language key in the model configuration file to
validate that the graph component is valid for usage with the specified language.
If a graph component returns None (this is the default implementation), it indicates
that the graph component supports all languages which are not part of
not_supported_languages.
Examples:
[]: The graph component does not support any languageNone: All languages are supported expect the languages defined innot_supported_languages["en"]: The graph component can only be used with English conversations.
not_supported_languages
The method not_supported_languages specifies which languages your
graph component does not support. Rasa will use the language key in the
model configuration file to validate that your graph component is valid for usage with
the specified language. If your graph component returns None (this is the default
implementation), you indicate that it supports all languages which are specified in
supported_languages.
Examples:
Noneor[]: All languages specified insupported_languagesare supported.["en"]: The graph component can be used with any language except English.
required_packages
The required_packages method indicates which extra Python packages need to
be installed to use this graph component. Rasa will raise an error
during execution if the required libraries are not found at runtime. By default, this method returns an empty list which implies that your graph
component does not have any extra dependencies.
Examples:
[]: No extra packages are required to use this graph component["spacy"]: The Python packagespacyneeds to be installed to use this graph component.
Model Persistence
Some graph components require persisting data during training which should be available
to the graph component at inference time. A typical use case is storing model
weights. Rasa provides the
model_storage and resource parameters to your graph component's create and load
method for this purpose as shown in the snippet below. The model_storage provides
access to data from all graph components. The resource allows you to uniquely identify
your graph component's location in the model storage.
Writing to the Model Storage
The snippet below illustrates how to write your graph component's data to the model
storage.
To persist your graph component after training, the train method will need to access
to the values of model_storage and resource. Therefore, you should store the values
of model_storage and resource at initialization time.
Your graph component's train method must return the value of resource so that Rasa can cache
the training results between trainings.
The self._model_storage.write_to(self._resource) context manager provides a path to
a directory where you can persist any data required by your
graph component.
Reading from the Model Storage
Rasa will call the load method of your graph component to instantiate it for inference. You can use the context manager self._model_storage.read_from(resource) to get a path to the directory where your graph component's data was persisted. Using the provided path you can then load the
persisted data and initialize your graph component with it. Note that the model_storage
will throw a ValueError in case no persisted data was found for the given resource.
Registering Graph Components with the Model Configuration
To make your graph component available to Rasa you may have to register your
graph component with a recipe. Rasa uses recipes to translate the content
of your model configuration to executable
graphs.
Currently, Rasa supports the default.v1 and the experimental graph.v1 recipes.
For default.v1 recipe, you need to register your graph component by using the DefaultV1Recipe.register
decorator:
Rasa uses the information provided in the register decorator and the
position of your graph component within the configuration file to schedule the execution
of your graph component with its required data. The DefaultV1Recipe.register decorator allows you
to specify the following details:
component_types: This specifies what purpose your graph component fulfills within the assistant. It is possible to specify multiple types (e.g. if your graph component is both intent classifier and entity extractor):ComponentType.MODEL_LOADER: Component type for language models. Graph components of this type provide pretrained models to other graph components'train,process_training_dataandprocessmethods if they have specifiedmodel_from=<model loader name>. This graph component is run during training and inference. Rasa will use the graph component'sprovidemethod to retrieve the model which should be provided to dependent graph components.ComponentType.MESSAGE_TOKENIZER: Component type for tokenizers. This graph component is run during training and inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will useprocess_training_datafor tokenizing training data examples andprocessto tokenize messages during inference.ComponentType.MESSAGE_FEATURIZER: Component type for featurizers. This graph component is run during training and inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will useprocess_training_datafor featurizing training data examples andprocessto featurize messages during inference.ComponentType.INTENT_CLASSIFIER: Component type for intent classifiers. This graph component is run only during training ifis_trainable=True. The graph component is always run during inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will use the graph component'sprocessmethod to classify the intent of messages during inference.ComponentType.ENTITY_EXTRACTOR: Component type for entity extractors. This graph component is run only during training ifis_trainable=True. The graph component is always run during inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will use the graph component'sprocessmethod to extract entities during inference.ComponentType.POLICY_WITHOUT_END_TO_END_SUPPORT: Component type for policies which don't require additional end-to-end features (see end-to-end training for more information). This graph component is run only during training ifis_trainable=True. The graph component is always run during inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will use the graph component'spredict_action_probabilitiesto make predictions for the next action which should be run within a conversation.ComponentType.POLICY_WITH_END_TO_END_SUPPORT: Component type for policies which require additional end-to-end features (see end-to-end training for more information). The end-to-end features are passed into the graph component'strainandpredict_action_probabilitiesasprecomputationsparameter. This graph component is run only during training ifis_trainable=True. The graph component is always run during inference. Rasa will use the graph component'strainmethod ifis_trainable=Trueis specified. Rasa will use the graph component'spredict_action_probabilitiesto make predictions for the next action which should be run within a conversation.
is_trainable: Specifies if the graph component is required to train itself before it can process training data for other dependent graph components or before it can make predictionsmodel_from: Specifies if a pretrained language model needs to be provided to thetrain,process_training_dataandprocessmethods of the graph component. These methods have to support the parametermodelto receive the language model. Note that you still need to make sure that the graph component which provides this model is part of your model configuration. A common use case for this is if you want to expose the SpacyNLP language model to your other NLU components.
Using Custom Components in your Model Configuration
You can use custom graph components like any other NLU component or policy within your
model configuration. The only change is that you have to specify
the full module name instead of the class name only. The full module name depends on
your module's location in relation to the specified
PYTHONPATH.
By default, Rasa adds the directory from where you run the CLI to the
PYTHONPATH. If you e.g. run the CLI from /Users/<user>/my-rasa-project
and your module MyComponent is in /Users/<user>/my-rasa-project/custom_components/my_component.py
then the module path is custom_components.my_component.MyComponent. Everything except
the name entry will be passed as config to your component.
Implementation Hints
Message Metadata
When you define metadata for your intent examples in your training data, your NLU component can access both the intent metadata and the intent example metadata during processing:
Sparse and Dense Message Features
If you create a custom message featurizer, you can return two different kind of
features: sequence features and sentence
features. The sequence features are a matrix of size (number-of-tokens x
feature-dimension), i.e.
the matrix contains a feature vector for every token in the sequence.
The sentence features are represented by a matrix of size (1 x feature-dimension).
Examples of Custom Components
Dense Message Featurizer
The following is the example of a dense message featurizer which uses a pretrained model:
Sparse Message Featurizer
The following is the example of a dense message featurizer which trains a new model:
NLU Meta Learners
Advanced use case
NLU Meta learners are an advanced use case. The following section is only relevant
if you have a component that learns parameters based on the output of previous
classifiers. For components that have manually set parameters or logic, you can create
a component with is_trainable=False and not worry about the preceding classifiers.
NLU Meta learners are intent classifiers or entity extractors that use the predictions of other trained intent classifiers or entity extractors and try to improve upon their results. An example for a meta learner would be a component that averages the output of two previous intent classifiers or a fallback classifier that sets it's threshold according to the confidence of the intent classifier on training examples.
Conceptually, to built a trainable fallback classifier you first need to create that fallback classifier as a custom component:
Next, you will need to create a custom intent classifier that is also a featurizer,
as the classifiers' output needs to be consumed by another component downstream.
For the custom intent classifier component you also need to define how its predictions
should be added to the message data specifying the process_training_data method.
Make sure to not overwrite the true labels for the intents. Here's a template that
shows how to subclass DIET for this purpose: